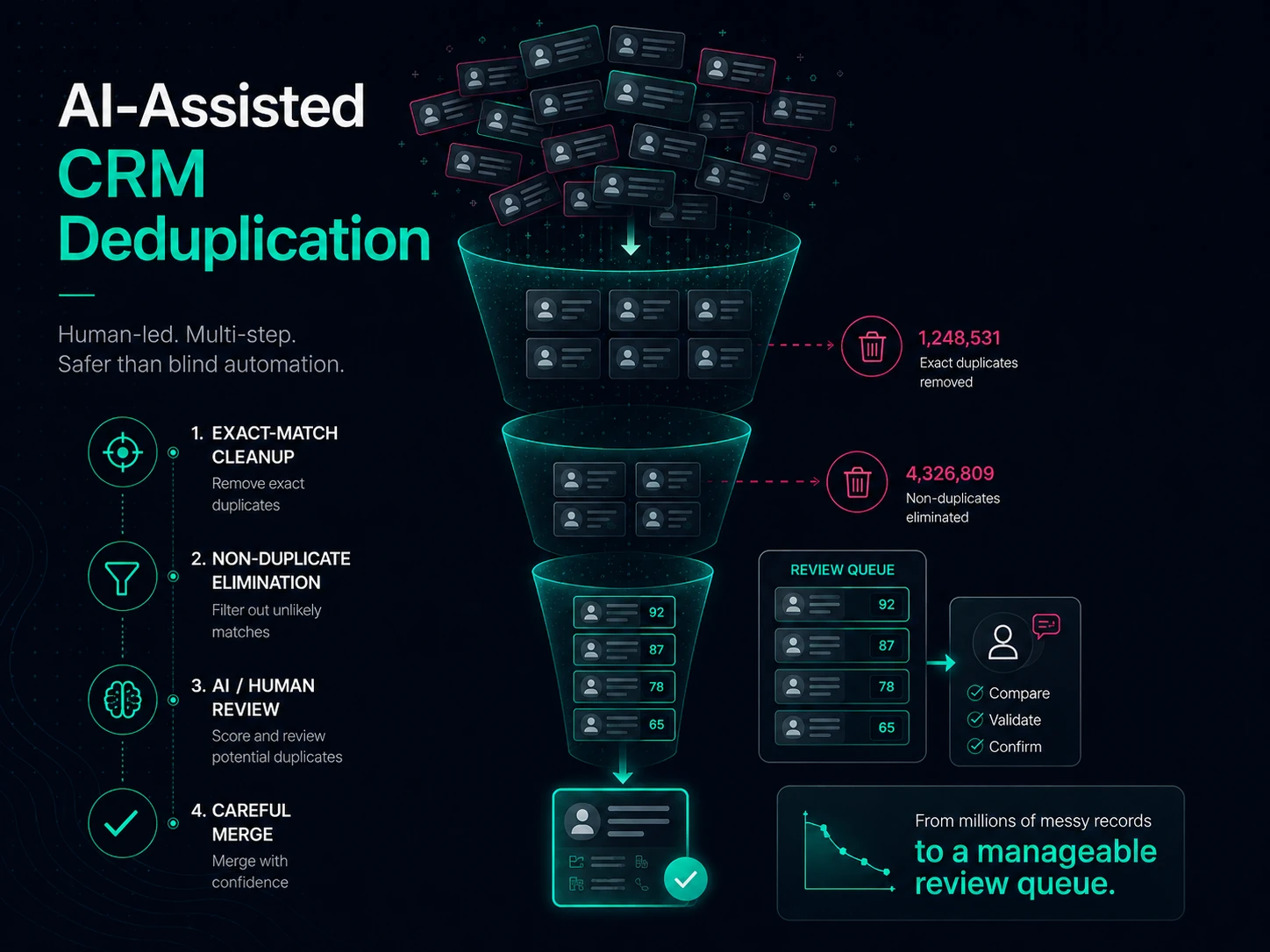
The workflow was designed as a four-phase process. The goal was not to automate merges. The goal was to make review possible without pretending the system had more certainty than it did.
Phase 1: Let Zoho catch exact matches.
Native Zoho CRM deduplication handles exact-match cases such as identical email or phone values. Those should be removed from the custom process before doing anything more expensive or interpretive. If two records match deterministically, there is no need to spend AI review effort on them.
Phase 2: Use Python to eliminate likely non-duplicates.
The script generates candidate pairs using blocking strategies — surname phonetics, company tokens, zip/name combinations, email local parts, street-number-plus-zip, and other recall-oriented passes. It then scores the pairs using independent signal families: email, phone, name, address, and company.
The scoring direction is intentionally inverted from what people expect. Positive scores mean evidence the records are not duplicates. Negative scores mean evidence they are duplicates. A pair is discarded only when multiple independent positive signals agree and no strong duplicate signal contradicts them.
Phase 3: Send the uncertain middle to AI and human review.
The output is not a merge file. It is a review queue. Each pair includes the score, category, blocking passes, and scoring contributors so the reviewer can see why the pair survived. That explanation layer matters. It keeps the review auditable instead of reducing the process to an unresolvable black box whose output must be accepted on faith.
Phase 4: Merge carefully in Zoho.
The final merge remains controlled. For Zoho CRM environments connected to Zoho Books, the Books-synced record may need to be selected as the master to avoid breaking accounting relationships or downstream sync assumptions. That is not the kind of decision an AI score should make casually.
What this looks like in practice.
Consider an example: two records with the same first name, same email, same phone, same address, and same company — but different surnames. In CRM data, this pattern is most often a name change, not two different people. Naive fuzzy matching tends to discard pairs like this because the name comparison fails badly. The inverted-scoring approach catches it reliably: matching email, phone, address, and company together produce a strong duplicate signal that easily outweighs the surname mismatch.
Importantly, in our approach, these records are not automatically resolved. In this case, the record pair lands in the high-confidence-duplicate review category, exactly where it belongs. This is a significant point of departure from other methods, which would auto-merge this pair or miss it entirely rather than flag it for review.